Chain-of-thoughts
插播
[!TIP] 文献结构与阅读方法 安大略理工大学的 Philips 教授认为,一般一篇论文的核心要素有以下几点:
SPL( Summary for previous literature ): 作者对前人文献的总结,包括概念辨析等CPL( Critique of previous literature ): 指出前人的研究局限WTD( What the dissertation does ): 指出这篇论文的 contributions, 意图等RAT( Rationale ): 研究理论框架RD( Research Design): 实验设计ROF( Research Outcome ): 实验结果RFW( Recommendations for Future Work): 未来实验方向 一般一篇文章的 abstract 就是按这个顺序来的 阅读完领域的一系列文章后,可以归纳总结一下他们的ROF的共性,SPL转化为CPL的办法, 以及参考他们的RFW
接着进入正题,解读这篇 LLM-reasoning 的经典文献
SPL & CPL: Training LLMs to reason
Problem to solve: Scaling up LLMs do not translate into better reasoning abilities in arithmetic, commonsense and symbolic reasoning
Two ideas are proposed to solve this problem
Pre-train or Fine-tune for Rationales
-
Core idea: Teaching LLMs to write intermediate reasoning steps with a dataset of questions-rationales-answers ( either by pre-training or fine-tuning)
-
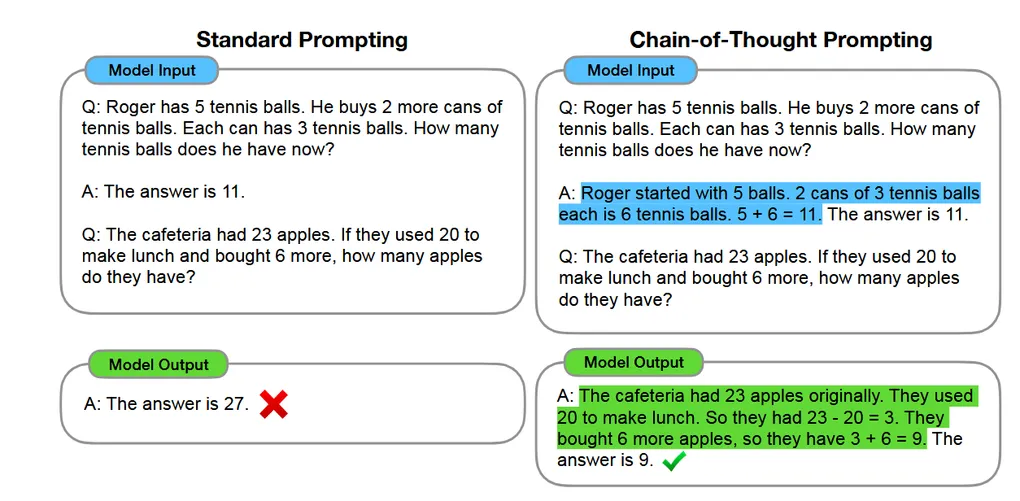
Example: The model generates “Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5 + 6 = 11. The answer is 11”
-
Pros: A direct way to tackle the reasoning problem. Improves interpretability since the reasoning process is transparent
-
Critiques: a large set of high-quality rationale bank is too expensive to be manually crafted, and transferability is not guaranteed.
Few-shot learning with examples in prompts
A new paradigm proposed by LLMs are few-shot learners, called “in-context learning”
- Core idea: Give demonstrations in prompts to let models learn in context and perform novel tasks. In-context learning improves drastically when models scale up
- Pros: Removes the expenses of fine-tuning and large datasets for each task, and is generalizable
- Cons: When prompted with ( question, answer ) pairs on reasoning problems, models tend to fail at jumping to conclusions
WTD: Proposing chain-of-thought prompting
Core technique: Prompt models with (inputs, chain-of-thoughts, outputs)
Motivation (How this method is derived)
- Human thinking: Human always think step-by-step in reasoning, especially for math problems
- Therefore, CoT inherits the idea of step-by-step thinking due to its significance
- CoT is based on the framework of in-context learning, leveraging LLM’s meta-learning abilities
- In short, CoT extracts the key idea of Step-by-step reasoning and integrates it with the in-context framework, aiming to teach models to reason by offering CoT examples based on their transfer learning abilities.
Why this works?
Let’s make a comparison between Q-A prompting and Q-CoT-A prompting
For standard Q-A prompting, this forces the model to make a massive, computationally expensive leap from questions to answers, where logical reasoning processes are hidden. What models really learn are not reasoning abilities but reciting Q-A pairs, hampering transferability and accuracy
However, a prompt like Q-step1-step2-step3-A offers a simpler path, instructing the model to make small, logical step each time. Besides, it also offers space for the models to think, and potentially debug
In terms of future prospects, CoT may have the potential to solve any reasoning tasks in natural language, and can be elicited with a relatively low cost.
RD & ROF: CoT on arithmetic, commonsense and symbolic reasoning
This study conducts a direct comparison between standard Q-A prompting and Q-CoT-A prompting on arithmetic, commonsense and symbolic reasoning tasks.

Additionally, the tests introduces model size as a key variable.
Key outcomes include:
- Dramatic improvements of CoT prompting emerges when models scale up. Specifically, small models produce fluent but illogical CoTs. This means multi-step reasoning abilities spring up after a certain threshold in scaling up
- CoT Prompting works better for complicated problems, like GSM8K maths problem set
- From examining CoTs generated by LaMDA 137B in correct and incorrect examples, researchers found that typically CoTs maintain accurate in both cases. Specifically, 50% errors are typically produced by minor mistakes in calculation or symbol mismatches, and 50% other errors are produced by major errors in CoT.
Additionally, Ablation experiments are conducted to rule out the possibilities that CoT may just help models extract equations out of natural language, extend computing time costs, or reason after answers. CoT also proves to be robust against exemplar variations in CoT examples
RFW: Limitations and future directions
- Essence of reasoning in Models is not clear: Models may not be reasoning in the pattern of human thinking.
- CoT prompting still relies on scaling up: Future works can delve into training reasoning abilities in small models
- Improving accuracy during reasoning
- CoT may still be impractical to Fine-tuning: leaves spaces for applying synthetic data to reduce costs.